blog
An overview of running your databases on and with Kubernetes

While Kubernetes (K8s) was originally designed for stateless workloads, advancements over the years, including enhanced support for Persistent Volumes, StatefulSets, and Operators, have made it possible to run stateful applications on Kubernetes. y
These new features and Kubernetes’ inherent scalability and resilience have made it an attractive platform for deploying databases. As a result, many organizations are already operating their databases on Kubernetes, and many more are eager to follow suit. However, some organizations are skeptical about running databases on K8s in production.
This blog will start by walking you through the history of database deployments. After that, it will discuss running databases on Kubernetes in 2024 and running databases with Kubernetes using the Severalnines’ CCX for CSP.
A brief history of database deployments: from mainframe to the cloud and container revolution
The evolution of database deployment reflects the ever-changing landscape of IT infrastructure and the growing demands of modern applications. From humble beginnings with mainframe computers, we’ve witnessed a shift towards greater abstraction, automation, and flexibility.
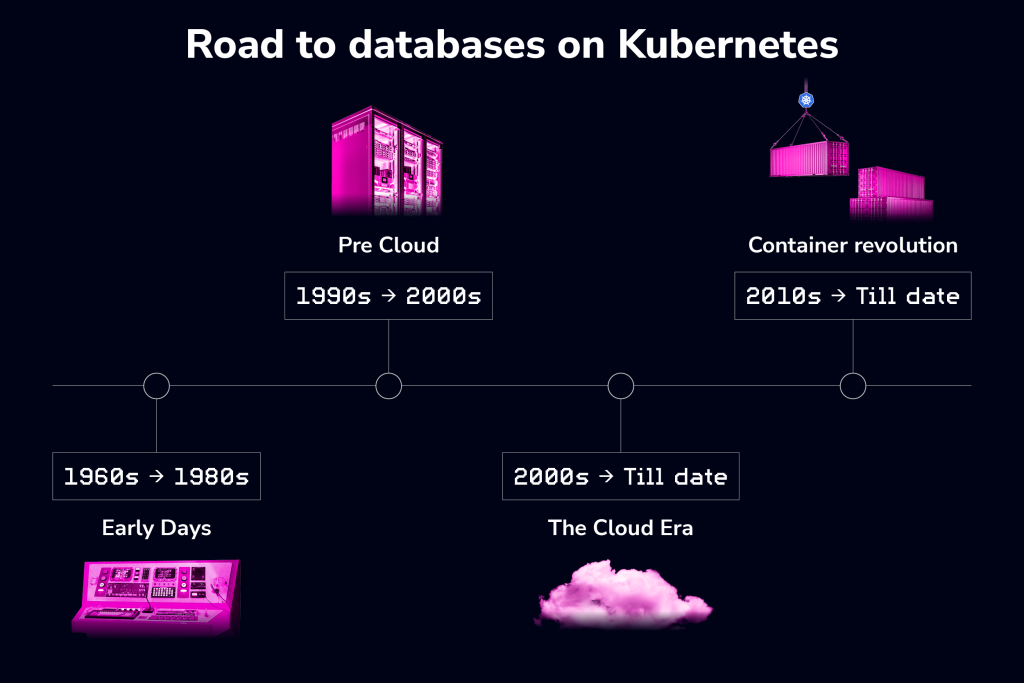
Early days of database deployments
In the early days of databases — 1960s, vast amounts of data were stored in the world’s new mainframe computers—many of them IBM System/360 machines. While revolutionary at the time, this approach came with limitations in terms of cost and rigid data models (a network model called CODASYL and a hierarchical model called IMS).
To solve the problem of rigid data models, Oxford-educated mathematician Edgar “Ted” Codd, published a paper in 1970 that introduced the relational database, and his ideas changed the way people thought about databases.
Several advancements in technology led to the creation of smaller servers over the years to reduce computer costs, maintenance, accessibility, etc.
Pre-Cloud Era
Before cloud computing, organizations had to buy and manage their own hardware and software for databases, which was expensive and inflexible, especially for smaller and newer companies. This paved the way for cloud computing, which promised easier and more affordable database solutions.
It’s worth noting that on-premises database deployments remain relevant and continue to grow in today’s Cloud-First Age. Industries and organizations with specific requirements such as data sovereignty, regulatory compliance, low-latency access, and other use cases, drive continued growth and innovation in on-premises deployments.
The Cloud Era
The rise of cloud computing marked a significant turning point in database deployment in the late 2000s and early 2010s. Cloud-managed databases, offered by large cloud providers (hyperscalers), simplified the provisioning and management of database infrastructure. The heavy lifting of hardware procurement, maintenance, and scaling was offloaded to the cloud provider, allowing organizations to focus on their applications.
Database-as-a-service (DBaaS) solutions further abstracted away the underlying complexities. DBaaS offerings provided on-demand, scalable databases with pay-as-you-go pricing models. This democratized access to databases, making them more accessible and cost-effective for businesses of all sizes.
The Container Revolution
With Docker as the leading platform, Container technologies revolutionized application deployment, including databases. Containers package applications and their dependencies into isolated, portable units, ensuring consistent behavior across different environments. This facilitated easier and faster deployment of databases across various platforms, from development to production.
In the late 2010s, Kubernetes emerged as the de facto standard for orchestrating and managing containerized applications. Kubernetes provides powerful automation and scaling capabilities, enabling the deployment, management, and scaling of complex systems across large clusters of machines.
The road to databases on Kubernetes started in its early days with the introduction of robust support for StatefulSets (initially known as “PetSet”) in version 1.5, released in 2016.
Running Databases on Kubernetes in 2024
Databases on Kubernetes have come a long way in the past five years. In February 2018, Kelsey Hightower, an early contributor and evangelist of Kubernetes, made a X thread on why he wouldn’t run stateful workloads on Kubernetes. Fast-forward to February 2023, he made another thread saying “ You can run databases on Kubernetes because it’s fundamentally the same as running a database on a VM.”
This shows how Kubernetes data workloads have come a long way since the introduction of StatefulSets.
The improvements and adoption of databases on Kubernetes wouldn’t have been possible without the Data on Kubernetes Community(DoKC). The DoKC was founded in 2020 to advance the use of Kubernetes for stateful and data workloads, and unite the ecosystem around data on Kubernetes (DoK).
Since its inception, the DoKC has helped hundreds of organizations and individuals deploy databases on Kubernetes through its resources, meetups, reports and events.
How to run databases on Kubernetes
How you run databases on Kubernetes today depends on your organization, the databases you want to run, and your team’s technical expertise.
Running databases on Kubernetes involves the separation of the control and data plane layers. By default, Kubernetes has this separation with the Kubernetes API server acting as the interface for its data plane to request computing resources, while the control plane takes care of mapping those requests to the underlying IaaS platform.
This default Kubernetes separation can be applied to database management on Kubernetes with Operators taking the role of the control plane. Operators are agents in Kubernetes that have the responsibility to reconcile the current state with the desired state.
Learning to deploy databases on Kubernetes manually and then worrying about performing Day 2 operations such as scale up/out, upgrades, security, etc. introduces operational overhead in your organization and does not truly unlock the value of using Kubernetes.
With operators, you can utilize constructs like Custom Resource Definitions (CRDs) and the resulting Custom Resource (CRs) to simplify database deployments on Kubernetes.
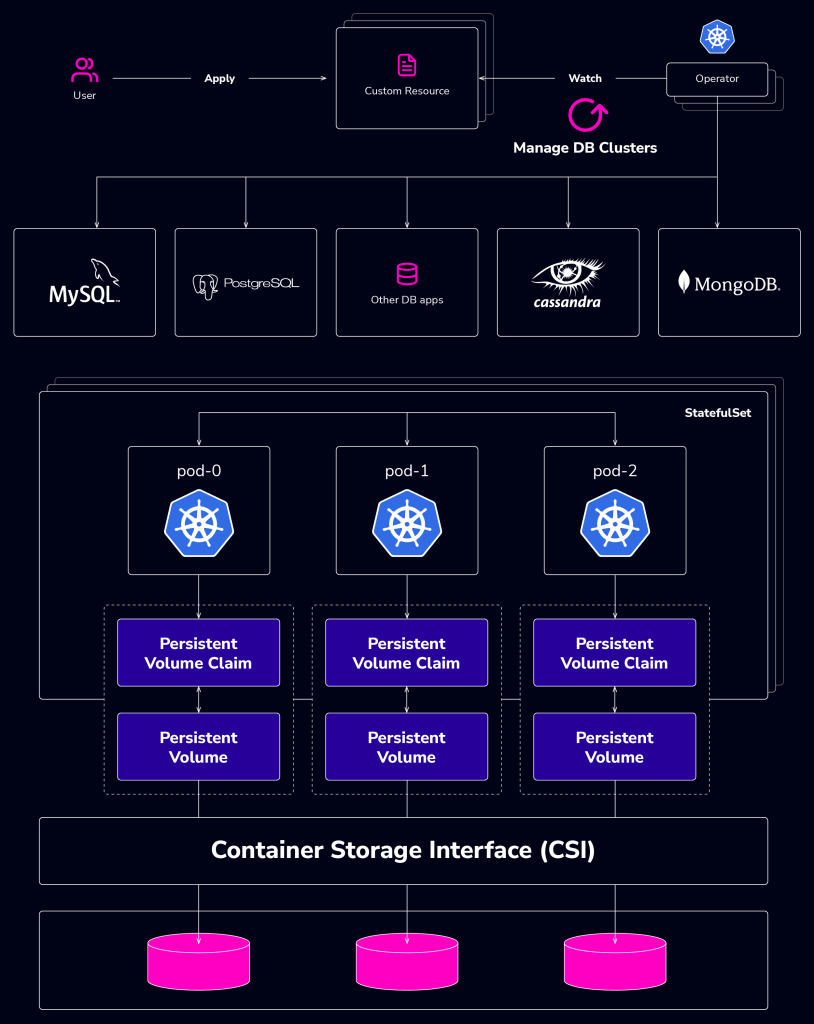
Image source: Data on Kubernetes whitepaper
More detailed information can be found in the whitepaper created by the Cloud Native Computing Foundation (CNCF) Storage TAG and the DoKC, Data on Kubernetes – Database Patterns Whitepaper. The whitepaper describes the patterns of running databases on Kubernetes.
The central message is clear: the decision to run databases on Kubernetes should align with your overall infrastructure strategy. For example, if the majority of your applications and services are not running on Kubernetes, then deploying your databases on Kubernetes may not yield the optimal benefits. And this is true because users won’t be able to provision full environments.
3 reasons for running databases on Kubernetes
Now that you have a brief overview of running databases on Kubernetes; now the question is, “Why would I want to run databases on Kubernetes? What is the gain?” Here are 3 key reasons:
- To break vendor lock-in: When organizations start using a cloud DBaaS, they slowly become ensnared in the single vendor’s ecosystem and face several challenges, such as limited flexibility, reduced bargaining power, higher costs etc. By running databases on Kubernetes, organizations can gain the flexibility to move their workloads across different cloud providers or on-premises environments without significant changes.
- Scalability and elasticity: Kubernetes makes it easy to scale database resources up or down dynamically based on demand, ensuring they can handle varying workloads without over-provisioning resources or experiencing performance bottlenecks.
Yes, Kubernetes tops out at 5000 nodes per cluster and 110 pods per node, but with micro-clusters, the bottleneck is removed enabling an enormous scale.
- High availability and resilience: Kubernetes provides built-in mechanisms for self-healing and failover, ensuring that your databases remain available even in the event of node failures or other disruptions.
For more reasons as to why you should consider running databases on Kubernetes, check out this Sovereign DBaaS Decoded podcast episode – Mad world – creating a new stateful world with Kubernetes – with Eddie Wassef, VP and Cloud Architect for Vonage.
Concerns with running databases on Kubernetes
Running databases on Kubernetes provides great benefits, and many organizations are championing this approach. However, just like there was a time when people felt uncomfortable running a database on virtual machines, organizations, and individuals have concerns today. The following are two general concerns:
Complexity of Operators?
About a year ago in a conversation on LinkedIn, a DevOps lead shared an experience with a Postgres operator, highlighting issues from image policy, maintaining the database cluster to fine-tuning the database which resulted in migrating DBs back to VMs and bare-metal servers.
One can understand the overall cost of the experience and why they resulted in returning to VMs.
Beyond technical issues, the additional abstraction layer makes it difficult to understand the underlying processes and behaviors, especially for users who are not intimately familiar with Kubernetes or using closed source operators.
Expertise and documentation
One can argue that the complexity of operators is due to a shortage of expertise and issues with documentation. The 2022 Data on Kubernetes report showed that lack of talent was one of the top challenges facing the adoption of data on Kubernetes. Kubernetes has “many moving parts,” and good understanding, experience, and detailed documentation are critical to properly managing databases on Kubernetes.
It is important to note that every case is different, and every organization has different database needs and capacity. Some organizations run absolutely massive stateful workloads on Kubernetes and are happy about it, while others run bare metal or managed (think RDS) databases and are unhappy. And vice versa.
But then again, you may ask, “Can I enjoy the benefits of Kubernetes without having to move my workload from VMs?” We say, “Yes!!”, which brings us to the next section of this blog.
Running Databases with Kubernetes
When we say “Running Databases with Kubernetes,” we mean using Kubernetes to manage data on VMs where the databases themselves aren’t directly deployed on Kubernetes.
There are several ways to use Kubernetes to deploy and manage your database infrastructure. At Severalnines, we built CCX for CSPs(Cloud Service Providers), a Kubernetes-based DBaaS that helps CSPs enhance their customers’ optionality for where their data stack is located and provision high-availability databases on OpenStack infrastructure resources and other VM providers.
CCX could also be implemented by teams who want to provide DBaaS internally e.g. platform engineering teams can implement CCX to take control of their data resources while providing the same end-user experience to their development teams as traditional DBaaS, like AWS RDS.
CCX Architecture
Built on the industry-leading ClusterControl(CC) platform by a team with extensive database automation, monitoring, and management expertise, CCX is based on a loosely coupled architecture, which means it is highly customizable — you can choose to use a different DNS service, metrics server, etc. — and gives you control over how you deploy and manage your database infrastructure.
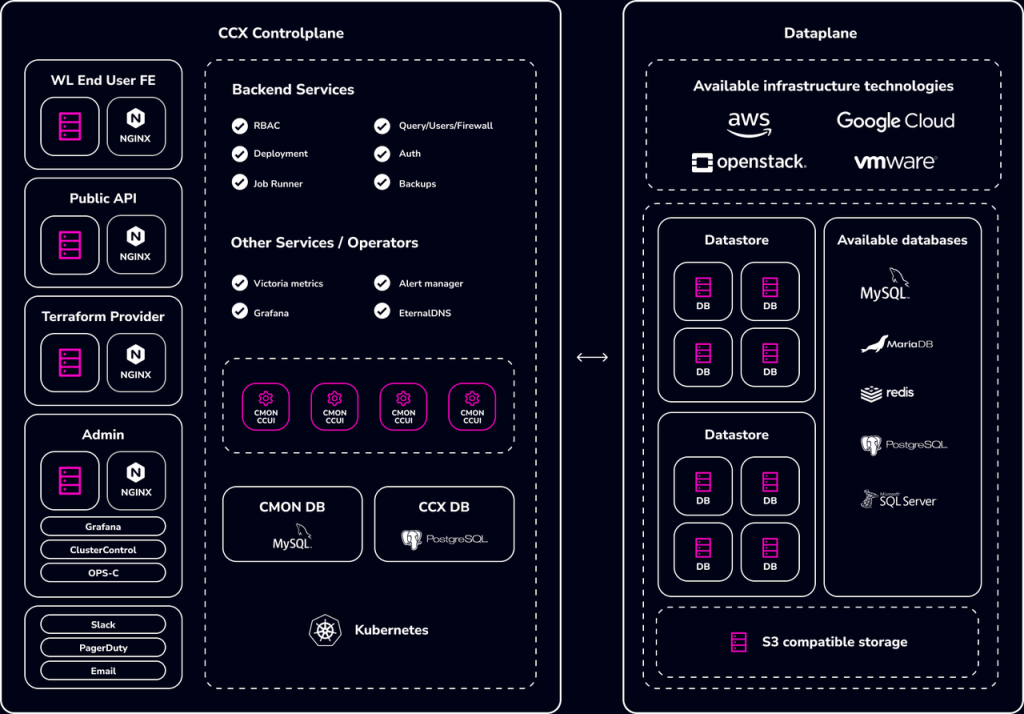
As you can see in the above architecture diagram, you would deploy CCX on Kubernetes. Kubernetes acts as the control plane, running CCX core backend services, including CCX UI, backup services, authentication services, CCX observability stack, etc.
Dataplane
With CCX deployed on Kubernetes, users can deploy vanilla open-source and proprietary databases on OpenStack infrastructures, WMware, AWS EC2 instances, and GCP VMs. They can also automate the lifecycle and Day 2 Ops of these databases just as in a regular cloud DBaaS.
CCX currently supports MySQL, MariaDB, Redis, PostgreSQL, and MS SQL Server, with support for more databases coming soon.
Interface
CCX provides a simple-to-use interface for your end users with access to powerful features. With the Admin interface, you can monitor users and manage thousands of deployed databases across your cloud.
The Terraform provider for CCX enables DevOps teams to deploy and manage database infrastructure with Terraform. The REST-based API also lets you easily integrate CCX directly with your existing workflows.
Key features of CCX
With a focus on sovereignty and control, CCX gives you the features you would want in any DBaaS plus more including:
- Effortless deployment: Empower your end users to provision high-availability databases on your infrastructure resources with just a few clicks.
- Open-source focus: CCX supports popular open-source databases, such as MySQL, MariaDB, and PostgreSQL, providing users with flexibility and avoiding vendor lock-in.
- Seamless failover and auto-recovery: Enable your end users to monitor their databases’ health and proactively address potential issues, minimizing downtime.
- Powerful backups and disaster recovery: Equip your end users with robust tools to implement sophisticated backup and disaster recovery strategies, ensuring minimal disruption to ops.
- Dynamic scaling options: With CCX end users can easily scale up, out, down or in, adjusting replicas and storage to meet their needs.
- Observability dashboards: With observability dashboards, your end users can gain insight into their data stacks’ performance, enabling them to pinpoint and address any issues.
To see CCX features in action, watch the CCX comprehensive demo here:
Why use CCX?
Organizations like Elastx and Lintasarta already use CCX and enjoy the following value propositions.
Value proposition for organizations:
- Implement a full-fledged, premium service quickly instead of committing a ton of R&D resources and time to build one from scratch.
- Provide greater value by offering a premium, DBaaS solution as an extension of your Cloud Services.
Fully customize the platform to meet your specific needs.
What’s in it for your end user?
- An intuitive end user portal to deploy, manage, and monitor database clusters.
- Advanced database knowledge is not required to leverage powerful features.
- True sovereignty over their data stack with a cloud-native experience.
- They can concentrate on their core business while maintaining compliance.
Conclusion
This blog post discussed how to run a database on Kubernetes and how you can run databases with Kubernetes using CCX. Just like in most aspects of a software development lifecycle, there are different approaches. Your choice of deploying on Kubernetes, with Kubernetes or any other means, depends on your needs and capacity.
The journey of database deployment is far from over. As technology continues to evolve, so will the ways in which we deploy and manage our data.
To learn more about CCX, explore our CCX for CSP page, or reach out today to discover how CCX can elevate your business to new heights!
The journey of database deployment is far from over
The journey of database deployment is far from over. As technology continues to evolve, so will the ways in which we deploy and manage our data.
The journey of database deployment is far from over
The journey of database deployment is far from over. As technology continues to evolve, so will the ways in which we deploy and manage our data.
The journey of database deployment is far from over
The journey of database deployment is far from over. As technology continues to evolve, so will the ways in which we deploy and manage our data.